Tom Brown sent me a link to a highly critical comment from TallDave on Scott Sumner's blog the other day. I think it contains a decent critique, but also misunderstands the project. Here is TallDave's comment:
I think the problem with Jason’s math is that when translated into words you get assertions like what is called “demand” in economics is essentially a source of information that is being transmitted to the “supply”, a receiver, and the thing measuring the information transfer is what we call the “price” which are kind of silly on their face. Modelling economics as a function of information transfer is a bit like modelling the digestive process on the basis of food’s color when it enters and exits — it just doesn’t capture enough of the process to be a useful exercise.
Emphasis in the original. It is true that naively applying the language of communications channels to economics in this way would seem like an exercise in modeling by elaborate analogy. However, the information equilibrium approach really is just a generalization of the idea of supply meeting demand. Imagine the distribution of blueberries as a function of time and space. During the spring, they are mostly distributed near the farms where they are grown. During the summer, they are distributed among many grocery stores. Much like in the Arrow-Debreu formulation of general equilibrium, we have a blueberry at a point in space at a particular time that represents a blueberry "supply event". Let's say that probability distribution P(B) looks something like this:

Now a blueberry consumer has a property we call demand for blueberries. It changes in space and time as well. In the same way we have supply events, we have demand events (I have money for blueberries at the grocery store near my house at a given time today). In an ideal world, the distribution of blueberry supply events and the distribution of blueberry demand events [call it P(A)] would be identical:

These supply events and demand events together would form a joint distribution of "transaction events" where money was traded for blueberries:

This situation where the distribution of supply events and the distribution of demand events are the same is what we call information equilibrium. Information? If you check out any given Wikipedia page for a probability distribution (e.g. the normal distribution), you will see an entry in the box on the right-hand side for "Entropy" that links to the information entropy page.

Any probability distribution (e.g. our supply and demand distributions above) can be quantified in terms of its information entropy.
That's well and good for two identical distributions that don't change, but what happens if we infinitesimally wiggle one distribution [P(A)]? How much does the other distribution [P(B)] have to wiggle in order to maintain information equilibrium? The simplest answer to that question for uniform distributions gives us the information equilibrium condition (see e.g. here, except I used D and S instead of A and B):

The information in that wiggle δP(A) must have flowed (was transferred) to P(B). (Note that the P in the equation above is not the probability distribution, but the price which I will talk about below.) That's where the communication channel interpretation comes in. We have come complex multi-dimensional demand distribution and some multi-dimensional supply distribution with the information in the fluctuations of the demand distribution being transmitted through some channel and received by the supply distribution. (In a sense, Shannon's theory comes about from wanting the distribution of messages at one end to be identical to the distribution of messages at the other end.) This gives us the standard picture of a communication channel:
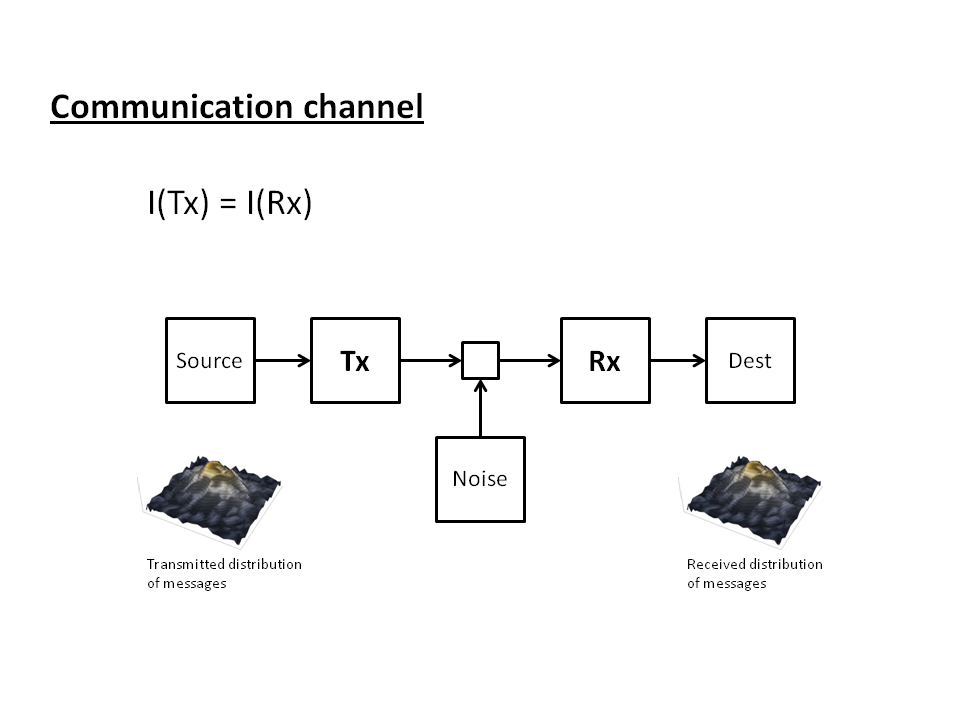
What about the price? I just defined the price in the equation above as the derivative dA/dB -- this is actually an abstract price and should really be considered an exchange rate for an infinitesimal unit of A for an infinitesimal unit of B. Does this make any sense? Yes, it does. For example, check out Irving Fisher's 1892 thesis:

The information equilibrium condition is just a minor generalization of the equation Fisher writes down relating the exchange of gallons of A for bushels of B. But there is more -- in fact, if you define the LHS of the information equilibrium condition as the price, you can use that equation to derive supply and demand curves (see my paper or this blog post).
For more theoretical motivation, I'd also recommend you check out my slides on the connection between information equilibrium and Gary Becker's paper Irrational Behavior and Economic Theory. For physicists, there's another theoretical motivation in terms of effective field theory (here, here).
There is a decent critique contained in TallDave's comment, though:
Modelling economics as a function of information transfer is a bit like modelling the digestive process on the basis of food’s color when it enters and exits — it just doesn’t capture enough of the process to be a useful exercise.
It is definitely possible that the information in the wiggles δP(A) are not received by the distribution P(B) -- information is lost. It could be the case that P(A) is a complex multi-dimensional distribution and P(B) is ... less complex. In that case (for uniform distributions), the best we can say is that information equilibrium is a bound on the information transfer

and we have what we call non-ideal information transfer. But does information equilibrium capture enough of the process to be useful? This should primarily be an empirical question, but I'd say yes for two reasons:
Therefore, I'd say there's really no reason to consider information equilibrium prima facie "silly". If information equilibrium is silly, so is supply and demand since they are formally identical. That may well be true -- but then economics in general would be silly.
Haters gonna hate...
ReplyDeleteThe real question is how many unique, useful predictions does this model make, and do they fit empirical evidence?
ReplyDeleteThat's the first bulleted link above; there are several predictions.
DeleteHowever I'd change "unique" to "diverse, quantitative". There are macro models out there for almost every possibility. Almost no model makes a unique prediction. But a model that makes one accurate prediction that's the same prediction as some other model that makes twenty accurate predictions doesn't lessen the quality of the latter model. The latter model incorporates a diversity of effects.
Quantitative (as opposed to qualitative) predictions are also very important. That is what uniqueness is really aiming for. I predict a 7.1% unemployment rate and you predict a 9.9% rate. They are both qualitatively in the same direction from today in the US. However they are different because they are quantitative.
But then there is Occam's razor. If two models make twenty accurate quantitative predictions but one is much simpler than the other, the simpler model wins. It should even win if it is slightly less accurate (your personal objective function for that optimization is completely subjective though). This is what happened with Copernicus. The new model made the same (and slightly worse accuracy) predictions as the Ptolemaic model (I.e. It wasn't unique). But we still think of it as an advance!
The real question is how many unique, useful predictions does this model make, and do they fit empirical evidence?
ReplyDelete