Something that I've never understood in my many years in the econoblogosphere as reader and eventually as a writer is the allure of Steve Keen. One of the first comments on my blog was from someone saying I should check him out. He wrote a book called Debunking Economics back in 2001, claims to have predicted the financial crisis (or maybe others claim that feather for him), and since then he's been a prominent figure in a certain sector of left-leaning economic theory. He's been the subject of a few posts I've written (here, here, here, and here). But mostly: I don't get it. Maybe the nonlinear systems of differential equations are shiny objects to some people. It might just be the conclusions he draws about economics (i.e. "debunking" it), debt, and government spending ‒ although the words "conclusions" and "draws" should probably be replaced with "priors" and "states". Hey, I love lefty econ just as much as the next person.
UnlearningEcon suggested that Keen made ex ante qualitative predictions using his models:
Keen (and Godley) used their models to make clear predictions about crisis
This statement along with the accompanying discussion of qualitative models are what inspired this series of posts (Part 1 is here, where I lay out what we mean by qualitative analysis; Part 3 will be about Godley's models). There are some that say Keen predicted the financial crisis, but there are several things wrong with this.
He only appears to have predicted in 2007 [pdf] that housing prices would fall for Australia. First, this is after the housing collapse already started in the US (2005-2006). The global financial crisis was starting (the first major problem happened 7 Feb 2007, almost exactly 10 years ago, and that pdf is from April). Additionally, housing prices didn't fall in Australia and Keen famously lost a bet. And note that the linked article refers to him as the "merchant of gloom" ‒ Keen had already acquired a reputation for pessimism. Aside from this general pessimism, there do not appear to be any ex ante predictions of the financial crisis.
Ok, but UnlearningEcon said predictions about the crisis. Not necessarily predictions of the crisis. That is to say Keen had developed a framework for understanding the crisis before that crisis happened, and that's what is important.
And with some degree of charity, that can be considered true. Most (all?) of Keen's models appear to have a large role for debt to play, and in them a slowdown in the issuing of debt and credit will lead to a slowdown in the economy (GDP). Before the housing crisis, the US had rising levels of debt. Debt levels (we think) cannot continue to rise indefinitely (relative to GDP), so at some point they must level off or come back down. And the financial crisis was preceded by a slowdown in the US housing market.
The problem with this is that Keen's model defines GDP' as output (Y, i.e. what everyone else calls GDP without the prime) plus debt creation (Y + dD/dt ~ GDP') (see here or here for discussion). Therefore it comes as no surprise that debt has an impact on GDP'. And since debt cannot increase forever (we think), it must level off or fall if it is currently rising. Therefore there must eventually be an impact to GDP'. And due to Okun's law, that means an impact on employment.
That is to say those qualitative predictions of the model (slowdown in debt creation will lead to fall in GDP') are in fact inputs into the model (Y + dD/dt ~ GDP'). I think JW Mason put it well:
Honestly, it sometimes feels as though Steve Keen read a bunch of Minsky and Schumpeter and realized that the pace of credit creation plays a big part in the evolution of GDP. So he decided to theorize that relationship by writing, credit squiggly GDP. And when you try to find out what exactly is meant by squiggly, what you get are speeches about how orthodox economics ignores the role of the banking system.
Basically we have no idea why we decided debt creation is a critical component of GDP' besides some chin stroking and making serious faces about debt. Making serious faces about debt has been a pasttime of humans since the invention of debt. However! Shouldn't we credit Keen with the foresight to add debt to the model regardless of why he did it? Maybe he hadn't quite worked out the details of why that dD/dt term goes in there, but intuition guided him to include it. The inclusion lead to a model that Keen used to make qualitative predictions, therefore we should look at the qualitative properties of the models. I'll drop the prime on GDP' from here on out.
This is where that series of tests I discussed in Part 1 comes into play. Most importantly: you cannot use a qualitative prediction to validate a model as a substitute for (qualitatively) validating it with the existing data. Let's say I have a qualitative model that qualitatively predicts that a big shock to GDP (and therefore employment by Okun's law) is coming because the ratio of debt to GDP is increasing. Add in a Phillips curve so that high unemployment means deflation or disinflation. Now how would that look generically (qualitatively)? It'd look something like this:

Should we accept this model because of its qualitative prediction? Look at the rest of it:

It was a NAIRU model with perfect central bank inflation/employment targeting that added in Keen's debt mechanism (trivially) when debt reached 100% of GDP. But here is Keen's model from "A dynamic monetary multi-sectoral model of production" (2011):

The qualitative prediction is the same, but the qualitative description of the existing data from before the prediction is very different. Here we have two "Theory versus data" graphs:


Actually the simplistic model is a much better description (measured by average error) of the data! But neither really captures the data in any reasonable definition of "captures the data".
The issue with using Keen's models qualitatively is that they fail these qualitative checks against the existing data. Here are a couple more "Theory versus data" graphs (the first of real GDP growth is from the model above, the second is from Keen's Forbes piece "Olivier Blanchard, Equilibrium, Complexity, And The Future Of Macroeconomics" (2016)):


And I even chose the best part of the real GDP data (the most recent 20 years) to match up with Keen's model. But there's a lot more to qualitative analysis than simply looking at the model output next to US data. To be specific, let's focus on the unemployment rate.
Unemployment: a detailed qualitative analysis
First, Keen's graph not only doesn't look much like US data as mentioned:

It doesn't look much like the data from other countries either (here the EU and Japan):


Additionally, Keen's graphs don't share other properties of the unemployment data. Keen's model has strong cyclical components (I mean pure sine waves here), while the real data doesn't. We can see this by comparing the power spectrum (Fourier transforms) [1] (data is dotted, Keen's model is solid):

Another transform (more relevant to the information equilibrium approach) involves a linear transform of the logarithm of the data:
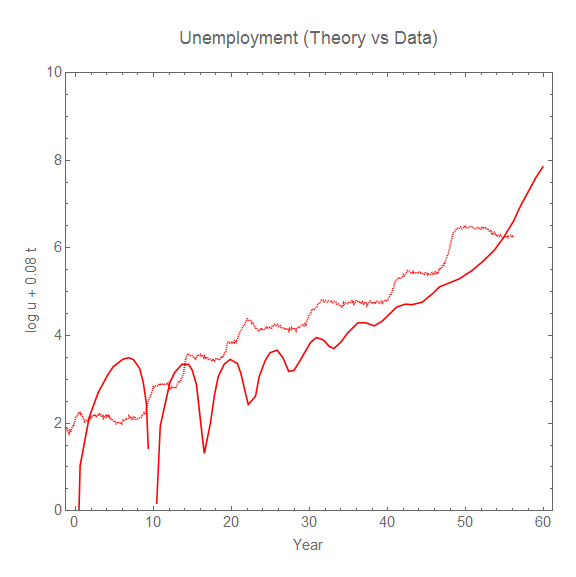
We can see the unemployment data has a strong step-like appearance, which is due to the roughly constant rate of fractional decrease in the unemployment rate after a shock hits [2]. This property is shared with the data from the EU and Japan shown above. Keen's model has the unemployment rate decreasing at a rate that is proportional to the height of the shock. Instead of flat steps, this results in trenches after each shock that decrease in depth as the shock decreases.
We can also observe that the frequency of the oscillation in Keen's model is roughly constant (it slightly decreases over time). However the differences between the unemployment peaks in the empirical data are consistent with a random process (e.g. Poisson process).
There's a big point I'd like to make here as well: just because you see the data as cyclic it doesn't mean any model result that is cyclic qualitatively captures the behavior of the system. I see this a lot out there in econoblogosphere. It's a bit like saying any any increasing function is same as any other: exponential, quadratic, linear. There are properties of cycles (or even quasi-periodic random events) beyond just the fact that they repeat.
Anyway, these are several qualitative properties of the unemployment data. In most situations these kinds of qualitative properties derive from properties the underlying mechanism. This means that if you aren't reproducing the qualitative properties, you aren't building understanding of the underlying system.
In fact, exponentially distributed random amplitude Gaussian shocks coupled with a constant fractional decrease in the unemployment rate derived from, say, a matching function yields all of these qualitative features of the data. Here's another "Theory versus data" using this model [3]:

The underlying system behind this qualitative understanding of the unemployment data has recessions as fundamentally random, predictable only in the sense that the exponential distribution has an average time between shocks (about 8 years). These random shocks hit, and then at a constant fractional rate the newly unemployed are paired with job openings.
Now it is true that the shocks themselves might originate from shocks in the financial sector or housing prices, or fluctuations in wealth and income (or all three). And there may be a debt mechanism behind how the shocks impact the broader economy. However, Keen's model does not even qualitatively describe how these pieces fit together.
So how does Keen's model stack up against the heuristics I put forward in my post on how to do qualitative analysis right? Well ...
- Keen's models generally have many, many parameters (I stopped counting after 20 in the model discussed above). The model discussed above The Lorenz limit cycle version from the Forbes piece appears to have 10. [4]
- If real RGDP is as above, then Keen's model does have a log-linear limit for RGDP growth. However, the price level fails to have a log-linear limit (since the rate goes from on average positive to increasingly negative, the price level will go up log-linearly and then fall precipitously).
- As shown, there is a time scale on the order of 60 years controlling the progression from cyclic unemployment to instability in addition to the roughly 7-8 year cyclic piece. This makes it pure speculation given the data (always be wary of time scales on the order of the length of available data, too).
- Keen's model is not qualitatively consistent with the shape of the fluctuations (per the discussion above).
- Keen's model is not qualitatively consistent with the full time series (per the discussion above).
The overall judgment is qualitative model fail.
...
Update 10 February 2017
One of the curious push-backs I've gotten in comments below is that Keen's model "is just theoretical musings", or that I am somehow against new ideas. The key point to understand is that I am against the idea of saying a model has anything to do with a qualitative understanding of the real world when the model doesn't even qualitatively look like the real world.
Keen himself thinks his model is more than just theoretical musings. He doesn't think the model just demonstrates a principle. He doesn't think these are just new ideas that people might want to consider. He thinks it is the first step towards the correct theory of macroeconomics. Here's the conclusion from Keen's "A dynamic monetary multi-sectoral model of
production" (2011):
Though this preliminary model has many shortcomings, the fact that it works at all [ed. it does not] shows that it is possible to model the dynamic process by which prices and outputs are set in a multisectoral economy [ed. we don't learn this because the model fails to comport with data]. ... The real world is complex and the real economy is monetary, and complex monetary models are needed to do it justice [ed. we don't know monetary models are the true macro theory]. ... Given the complexity of this model and the sensitivity of complex systems to initial conditions, it is rather remarkable that an obvious limit cycle developed [ed. limit cycles are not empirically observed] out of an arbitrary set of parameter values and initial conditions—with most (but by no means all) variables in the system keeping within realistic bounds [ed. they do not]. ... For economics to escape the trap of static equilibrium thinking [ed. we don't know if this the the right approach], we need an alternative foundation methodology that is neat, plausible, and—at least to a first approximation—right [ed. it is not]. I offer this model and the tools used to construct it as a first step towards such a neat, plausible and generally correct approach to macroeconomics [ed. it is not because it is not consistent with the data].
Keen's model does not "work", it does not capture the real world even qualitatively, it is not "right", and there is no reason to see this as a first step towards a broader understanding of macroeconomics because it is totally inconsistent with even a qualitative picture of the data.
In my view, Keen's nonlinear differential equations are travelling the exact same road as "rational expectations" approach of Lucas, Sargent, and Prescott. They both ignore the empirical data, but are pushed because they fit with some gut feeling about how economies "should" behave. In Keen's case, per JW Mason's quote above, where "credit squiggly GDP". With LSP [5], that people are perfect rational optimizers and markets are ideal. Real world data is seen through the lens of confirmation bias even when it looks nothing like the models. This approach is not science.
...
Footnotes:
[1] Interestingly, the power spectrum (Fourier transform) of the unemployment rate looks like pink noise with exponent very close to 1. Pink noise arises in a variety of natural systems.
[2] The constant rate is related to the linear transform piece and the fractional decrease is related to the logarithm piece.
[3] I also made this fun comparison of Keen's model, the data, and an IT dynamic equilibrium model:

[4] The random unemployment rate model produced from the information equilibrium framework has 2 for the mean and standard deviation of the random amplitude of the shocks, 2 for the mean and standard deviation of the random width of the shocks, 1 for the Poisson process of the timing of the shocks, and finally 1 for the rate of decline of the unemployment rate for a total of 6.
[5] Not Lumpy Space Princess, but Lucas, Sargent, and Prescott.
Keen's models are theoretical and designed to demonstrate a principle. They are not meant to represent real economies.
ReplyDeleteYour critique rests on beating up a straw man.
I
Which tenet of logic or science allows one to apply principles learned from a model that is not qualitatively consistent with reality to reality?
DeleteThat is to say: if you want to make these models but say the principles you are demonstrating are principles of completely fictitious alternate universes, that's fine. But if you want to say these principles apply to the real world, you need something that connects the model to reality. Usually that is being consistent with empirical data. I'm unaware of another way to connect a model with the real world.
"Not meant to represent real economies"? You mean, Keen is really a closet mainstream economist? ;)
DeleteHa! I just wrote almost the same thing on Twitter:
Delete"Nothing turns heterodox econ into orthodox econ faster than attempting to compare it to empirical data."
"The overall judgment is qualitative model fail."
ReplyDeleteI myself have critiqued Keen but agree with Anonymous' comment above. For example what Keen says about effective demand, GDP and change in debt and things such as that are either accounting errors in some cases and tautologies in other.
However, as anonymous says, it demonstrates a principle. How income, money, wealth and all are created and so on.
Keen's models after his errors are corrected are similar to SFC models in many ways.
Despite all that, it's still okay.
So it's stupid of you to say it's a model fail.
In physics, there's a quantum field theory that's taught called φ⁴ theory (see here). It's used to teach various principles from deriving Green's functions and the Feynman diagram representation of the Lagrangian to renormalization and the beta function.
DeleteHowever once that principle has been taught, that model is not then used to make predictions or do qualitative analysis. Instead you put together a real model that has some connection to empirical data. It is that connection to empirical data that gives the model weight and those principles applicability to the real world. If the model doesn't even qualitatively have properties of real world data, or those principles aren't connected to another model that does, then those principles are principles of imaginary worlds.
This comment has been removed by a blog administrator.
DeletePoint is even phi-fourth theory is good progress. Compare that to someone who doesn't even know basic calculus or refuses to believe QFT is a good framework.
DeleteAgain I do have issues with Keen's definitions and his claims ... despite that he seems to be quite in the right direction.
Anonymous -- no idea what your point is.
DeleteRamanan -- This is where even the heterodox become orthodox. Just like in mainstream econ (DSGE models and the like), there can be no progress in theory without connection to data. Theory work that does not connect to data is just a collection of mathematical musings. It is fine if you want to call it that.
However, mathematical musings on their own are not progress. Saying e.g. debt and credit cycles matter and putting together a model that says that is not progress until that synthesis connects to data qualitatively or quantitatively.
φ⁴ theory (which is used a pedagogical device in my example, not historical development of QFT) is just mathematical musings. However, the skills learned from the musings can be applied to QED which does connect to data. Only then do the principles learned in φ⁴ theory have any value.
Until that bridge to data is built, there is no progress in theory.
One of the nice things about physics is that it is set in a framework of theory that does connect to data. Therefore anything you build in that framework has at least some connection to data. Economics does not have that framework, so you have to behave as if every theoretical trek is a dead end until proven otherwise.
To paraphrase the Beastie Boys, No progress till data.
This comment has been removed by a blog administrator.
DeleteThis comment has been removed by the author.
DeleteThis comment has been removed by a blog administrator.
DeleteThis comment has been removed by the author.
DeleteThis comment has been removed by a blog administrator.
DeleteThis comment has been removed by a blog administrator.
DeleteThe Levy Institute has models based on SFC models which look to track at the US economy. Have a look.
DeleteWynne Godley and his colleagues used to model the UK economy as well. They weren't alone, although the only group to get it right in the 70s.
Have a look at this book: https://www.amazon.com/Keynesianism-Monetarism-Routledge-Revivals-macroeconometric/dp/041561239X/
A model in which debt matters than not matter is anyway progress.
Now to address your point about the phi-fourth theory. I know. I have a background in string theory. But phi-fourth theory is anyway better than an Aristotelian model or a model in which matter is infinitely divisible and so on. It illustrates.
My point was that your analogy with phi-fourth was not good to start with. But if you wanna play that physics comparison game, then I offered a better way to say it. As Keynes probably said: it's better to be approximately right than totally wrong. National accounts and flow of funds are the way statisticians measure economies. How the stocks and flows move forward in time is by no way so obvious.
But you should stop making these physics analogies. Totally not useful.
Again, there is no empirical evidence that debt plays a significant role in macro so its inclusion in a macro model is not necessarily progress. And a toy model that includes debt doesn't demonstrate any principles because, again, there is no evidence that debt plays a significant role in macro.
DeleteI brought up the φ⁴ theory because it is an example of toy models done right. Let me rewrite the above using it:
There is empirical evidence that renormalization plays a significant role in particle physics so its inclusion in a quantum field theory is progress. And a toy model like φ⁴ theory that includes renormalization does demonstrate principles because there is evidence that renormalization plays a significant role in quantum field theory.
debt → renormalization
macro → quantum field theory
Keen's model → φ⁴
no evidence → evidence
If you change "evidence" to "no evidence" then the rationale for φ⁴ (i.e. Keen's theory/including debt) disappears.
Again, please stop comparing to Physics. It's counterproductive.
Delete"Again, there is no empirical evidence that debt plays a significant role in macro so its inclusion in a macro model is not necessarily progress"
That's ridiculous. Doesn't everyone agree that Greece has a debt problem? I mean you must be the only person saying that Greece's problems aren't connected to its debt.
It's not just Greece, even in the financial crisis worldwide starting 2007, debt has importance. I'd love to know how many people apart from you do not believe it.
A better analogy would be a Yang-Mills theory with scalar fields around and the connection to data being parameters, the gauge group and so on. But simple Lagrangians illustrate a lot about behaviour from symmetry breaking to confinement to asymptotic freedom and so on.
Again, I think physics analogies shouldn't be used much.
Don't be obtuse.
DeleteKeen's models are about private/household/consumer debt (mortgages, credit), not government debt.
That is the same analogy.
"But simple Lagrangians illustrate a lot about behaviour from symmetry breaking to confinement to asymptotic freedom and so on."
The only reason it makes sense to use simple Lagrangians illustrate these things is that that have been demonstrated to be important empirically. We do not observe free quarks, therefore illustrating confinement with some simpler theory is useful.
Since we do not observe periodic credit cycles or complete economic collapse, building over-simplified models to understand these things is not useful. It is not empirically certain whether credit fluctuations are a cause or and effect of other factors in the macroeconomy. Therefore it does not make sense to build simple models where credit cycles are definitively the *cause* of macroeconomic fluctuations.
That is, unless you want to argue against the idea! Keen's models represent a really good argument against using nonlinear systems of differential equations and credit cycles to understand the macroeconomy. The results of those models look nothing like a real economy, therefore they must be barking up the wrong tree.
That is a perfectly acceptable use of Keen's models.
This comment has been removed by a blog administrator.
DeleteI am not sure how one can construe my point that you should discipline models with the empirical data with the Chicago school that famously built models with complete disregard for the empirical data.
DeleteThat's a good frame to understand how I see Keen: just like Bob Lucas, Tom Sargent or Ed Prescott with their rational expectations framework, Keen disregards the empirical data in favor of his framework. It will lead to the same place.
This comment has been removed by a blog administrator.
DeleteIt's fine if you want to just call them theoretical musings. But Keen does not say these are just musings. He says they're important results and advances:
DeleteThough this preliminary model has many shortcomings, the fact that it works at all [ed. it does not] shows that it is possible to model the dynamic process by which prices and outputs are set in a multisectoral economy [ed. we don't learn this because the model fails to comport with data]. ... The real world is complex and the real economy is monetary, and complex monetary models are needed to do it justice. ... Given the complexity of this model and the sensitivity of complex systems to initial conditions, it is rather remarkable that an obvious limit cycle developed [ed. limit cycles are not empirically observed] out of an arbitrary set of parameter values and initial conditions—with most (but by no means all) variables in the system keeping within realistic bounds [ed. they do not]. ... For economics to escape the trap of static equilibrium thinking [ed. we don't know if this the the right approach], we need an alternative foundation methodology that is neat, plausible, and—at least to a first approximation—right [ed. it is not]. I offer this model and the tools used to construct it as a first step towards such a neat, plausible
and generally correct approach to macroeconomics [ed. it is not because it is not consistent with the data].
If Keen had just said here's an interesting mathematical model with some weird dynamics that doesn't look anything like a real economy, that would be fine!
But he doesn't.
He claims that they are more than 'just' theoretical musings.
And you can't do that without connection to empirical data.
What is the source of this quote and who the "ed."?
Deletehttp://keenomics.s3.amazonaws.com/debtdeflation_media/papers/Keen2011DynamicMonetaryMultisectoralModel.pdf
DeleteThe editorial comments are from me.
This comment has been removed by a blog administrator.
DeleteEditorializing in a quote is a common practice. That you are unfamiliar with it does not impugn my integrity.
DeleteSo one of the model's "shortcomings" can be "inconsistent with reality" and you can still say that the model is applicable to reality?
What is happening here is that it's one of Pfleiderer's Chameleon models. It's used to say things about the real world, but when questioned, it's just tentative musings with shortcomings.
One or the other. Not both.
This comment has been removed by a blog administrator.
Delete"Don't be obtuse.
DeleteKeen's models are about private/household/consumer debt (mortgages, credit), not government debt."
I am not just talking of Keen's model but also Wynne Godley's models.
Anyway, private borrowing was also high before the crisis.
And what about the US? Are you arguing that private debt didn't matter for the US in causing the crisis?
Don't reply with "don't be obtuse". Just answer my question as to whether you think private debt matter or not and how many people share your view.
(Should have added: private borrowing was high in Greece before the crisis). Also it's not just about public debt but indebtedness to foreigners.
Delete"Just answer my question as to whether you think private debt matters or not "
DeleteI don't know the answer to that question. If there was some convincing theoretical argument that connected to data, then maybe I could be convinced.
The question of whether debt levels impact the macroeconomy should be exactly that: a question. Research should tell us that "yes, debt seems to matter", or "no, debt is not a causal factor". It shouldn't be assumed by fiat.
People who study macro tend to approach the study in this strange way. Instead of developing a framework to figure out what a recession is, the assertion of what causes a recession define the framework.
Since I'm not allowed to use physics analogies anymore, it's a bit like asserting all species extinctions are caused by meteors and working out a theory of evolution from there.
So-called "market monetarists" tell us that recessions are caused by the expectations the central bank sets -- and then proceed to work out macro theory from that assertion.
Godleys and Keens tell us that debt causes recessions, and then work out macro theory from that assertion.
Of course if you assume the cause of recessions, your model is going to parrot that assertion right back. Therefore it is unremarkable that Keen's model above tells us that high debt leads to a crisis. It might be interesting if that model also looked like empirical data when debt levels are low, but it doesn't.
Again, the framework you use to study a subject shouldn't assume things about the subject of study.
If I thought debt mattered to macro, I wouldn't assume a model where debt mattered to macro. I might assume a model where debt was included, but had a coefficient that would be set by empirical macro data.
For example, in Keen's models, he asserts things like Y + dD/dt ~ GDP. So much of the issues above could be avoided by using Y + c dD/dt ~ GDP and then using the empirical data to set c.
Godley et al's stock-flow models do a similar thing by including debt without a coefficient out front.
It would all be much more convincing if instead of saying there's a term + X, people said there's a term + c X and seeing if c isn't zero.
This comment has been removed by a blog administrator.
DeleteThe second graph shows the change in mortgage debt (by "mortgage debt accelerator" Keen just means change in M/GDP) versus the change in housing prices. So we have "discovered" that as housing prices go up, people take out bigger mortgages.
DeleteThe first graph shows that the change in credit issued is correlated with output. This does not say whether it is causal. The graph is also created in a strange way (it compares a percentage growth with a scaled level change). In fact, if you do it properly (i.e compare percent change in private credit to percent change in RGDP), you can see that the credit slumps follow the RGDP slumps:
https://fred.stlouisfed.org/graph/?g=cHu3
That means causality appears to go the other way from Keen's description: a shock to the economy hits and lending falls.
Regarding the Krugman comment, that is not what Krugman said.
If I decide to cut back on my spending and stash the funds in a bank, which lends them out to someone else, this doesn’t have to represent a net increase in demand. Yes, in some (many) cases lending is associated with higher demand, because resources are being transferred to people with a higher propensity to spend; but Keen seems to be saying something else, and I’m not sure what. I think it has something to do with the notion that creating money = creating demand, but again that isn’t right in any model I understand.
https://krugman.blogs.nytimes.com/2012/03/27/minksy-and-methodology-wonkish/
It's not that lending doesn't create demand (it does in "many" cases as stated above); the problem is why does demand depend on money growth -- why are we suddenly Friedman monetarist disciples looking at M2 growth?
Regarding the formula, it's not that I didn't understand it, it's that the quote from Keen tells you he is just asserting this. "it is economically and mathematically valid ..." but why? Adding "mathematically" valid is also complete jibberish. Of course it's mathematically valid to write down A + B = C. I guess that the "mathematically" just distinguishes A + B = C from A/0 ++++ B {} C. The latter isn't mathematically valid.
In any case, you shouldn't just accept graphs uncritically. It took me awhile to figure out what was being graphed because they don't make it very clear. But if you spend a little more time than none at all looking at the details, you can see that sometimes the graphs people put forward don't actually say what people say they say.
This comment has been removed by a blog administrator.
DeleteAny reason you removed my comment?
DeleteI removed all the anonymous comments that seemed to be from a single source that consistently repeats errors.
DeleteIf this was in error and you are a different anonymous commenter, then I apologize.
Let me direct you to my comment policy.
Apologies, but yes, this is a different Anonymous.
DeleteThat said, I don't believe anything I said in the previous comment was in error.
Perhaps some of these comments demonstrate why some "zombie" ideas never die. Any rational person should be able to immediately tell Keen's model fails qualitatively, which means it's useless, except as an example of what not to do.
ReplyDeleteMoreover, we should be striving for quantitatively predictive models, so we can see how much time some people in economics waste.
More generally, it's obvious just by listening to Keen that his model's wrong, given the unrealistic role he assigns to credit. It's expected money growth versus expected output potential that matters.
"Moreover, we should be striving for quantitatively predictive models, so we can see how much time some people in economics waste."
DeleteHa!
I'm with you all the way until that bit about expected money growth and expected output. There is no evidence that those things are keys to a successful macro theory because there haven't been a lot of qualitative or quantitative macro theory successes yet.
As I say to Ramanan above: no (theoretical) progress till data. Therefore we don't really know what the key to macro is. I have a model on this blog that tells us population growth is the key. As that model does describe the data fairly well, it deserves some weight when deciding which factors are the keys to macro.
I think your model is very interesting and may help solve some outstanding theoretical problems in the field, while also possibly revealing new phenomena, such as that revealed by your prediction that Canada would begin to undershoot its inflation target. I particularly like that it provides a ready and plausible explanation for the disconnect between micro and macro theory. It reminds me that I have to be open to the fact that my perspective on ZLB monetary policy could be very wrong.
DeleteHowever, I'm doing some simpler modeling that depends upon the assumption that expectations about money supply growth are key, and at least as far as event-modeling shocks is concerned, it's doing unreasonably well. That being said, we know that mere event modeling isn't econometrically rigorous, so I'm trying to find enough data of the right kind to better test the model.
Since I'm developing portfolio stress-testing software based on my model, I can't reveal too much more now, but it allows for a deterministic approach to stress-testing. As far as I know, this makes it unique.
I can share the simple approach I use to modeling changes in U3 unemployment.
U3 unemployment = 1 - 1 / [ U + %G - %W (1 + %P)]
Where:
U = baseline U3 unemployment rate
%G = % change in NGDP growth below trend
%W = % change in total labor costs(usually wages), where total labor cost = total hourly labor compensation + taxes and other costs of hiring
%P = change in labor productivity, where labor productivity = RGDP/labor hour
But, for sudden negative NGDP shocks, the above formula reduces to this, to give the total unemployment rate:
U3 uemployment = 1 - 1 / (U - %G)
It can be simplified, because total labor cost and labor productivity don't change(much) during a rapid fall in NGDP.
Apply that unreasonably simple model and you get a max. 24.9% unemployment rate for the Great Depression, and a max. 10.1% rate for the Great Recession, for example, which are extremely close to the recorded values.
Event testing for changes in broad representative stock indexes, real and nominal interest rates, gold, etc. do about as well.
Is that first equation supposed to be something like U(t+1) = 1 - 1/(U(t) + ... )?
DeleteYes, that's right. I'm rusty in math, having only taken up to calc 1 and a couple of stats courses, and that was many years ago now. I also use Excel, but may try another program soon, given how quickly and ably you process data. I'm very impressed. Maybe I'll give Mathematica a try.
DeleteI should point out that obviously both of the above equations model events. Obviously, a recursive form is required to move beyond that.
DeleteThis comment has been removed by a blog administrator.
DeleteAnonymous,
DeleteLet's say I posited a model a = f(x,y,z) that had one parameter k. I then fit that parameter to data. According to you, this "barely involves theory".
Now let k = G, a = F, x = m1, y = m2, and z = r so that:
F = G m1 m2/r²
That's Newton's universal gravitation law, and the "curve fitting" established the gravitation constant:
G = 6.67408 × 10-11 m^3 kg^-1 s^-2
But it's just "curve fitting". Newton didn't make any theoretical progress.
Oh, wait he did.
So maybe you see why I think you are suffering from the Dunning-Kruger effect?
This comment has been removed by a blog administrator.
DeleteSorry, I have no time for cases of Dunning-Kruger.
Delete