Something that I've never understood in my many years in the econoblogosphere as reader and eventually as a writer is the allure of Steve Keen. One of the first comments on my blog was from someone saying I should check him out. He wrote a book called
Debunking Economics back in 2001, claims to have predicted the financial crisis (or maybe others claim that feather for him), and since then he's been a prominent figure in a certain sector of left-leaning economic theory. He's been the subject of a few posts I've written (
here,
here,
here, and
here). But mostly: I don't get it. Maybe the nonlinear systems of differential equations are shiny objects to some people. It might just be the conclusions he draws about economics (i.e. "debunking" it), debt, and government spending ‒ although the words "conclusions" and "draws" should probably be replaced with "priors" and "states". Hey, I love lefty econ just as much as the next person.
UnlearningEcon suggested that Keen made ex ante qualitative predictions using his models:
Keen (and Godley) used their models to make clear predictions about crisis
This statement along with the accompanying discussion of qualitative models are what inspired this series of posts (Part 1 is
here, where I lay out what we mean by qualitative analysis; Part 3 will be about Godley's models). There are some that say Keen predicted the financial crisis, but there are several things wrong with this.
He only appears to have predicted
in 2007 [pdf] that housing prices would fall for Australia. First, this is after the housing collapse already started in the US (2005-2006). The global financial crisis was starting (the first major problem happened 7 Feb 2007, almost exactly 10 years ago, and that pdf is from April). Additionally, housing prices didn't fall in Australia and Keen
famously lost a bet. And note that the linked article refers to him as the "merchant of gloom" ‒ Keen had already acquired a reputation for pessimism. Aside from this general pessimism, there do not appear to be any ex ante predictions of the financial crisis.
Ok, but UnlearningEcon said predictions about the crisis. Not necessarily predictions of the crisis. That is to say Keen had developed a framework for understanding the crisis before that crisis happened, and that's what is important.
And with some degree of charity, that can be considered true. Most (all?) of Keen's models appear to have a large role for debt to play, and in them a slowdown in the issuing of debt and credit will lead to a slowdown in the economy (GDP). Before the housing crisis, the US had rising levels of debt. Debt levels (we think) cannot continue to rise indefinitely (relative to GDP), so at some point they must level off or come back down. And the financial crisis was preceded by a slowdown in the US housing market.
The problem with this is that Keen's model
defines GDP' as output (
Y, i.e. what everyone else calls GDP without the prime) plus debt creation (
Y + dD/dt ~ GDP') (see
here or
here for discussion). Therefore it comes as no surprise that debt has an impact on GDP'. And since debt cannot increase forever (we think), it must level off or fall if it is currently rising. Therefore there must eventually be an impact to GDP'. And due to Okun's law, that means an impact on employment.
That is to say those qualitative predictions of the model (slowdown in debt creation will lead to fall in GDP') are in fact inputs into the model (
Y + dD/dt ~ GDP'). I think
JW Mason put it well:
Honestly, it sometimes feels as though Steve Keen read a bunch of Minsky and Schumpeter and realized that the pace of credit creation plays a big part in the evolution of GDP. So he decided to theorize that relationship by writing, credit squiggly GDP. And when you try to find out what exactly is meant by squiggly, what you get are speeches about how orthodox economics ignores the role of the banking system.
Basically we have no idea why we decided debt creation is a critical component of GDP' besides some chin stroking and making serious faces about debt. Making serious faces about debt has been a pasttime of humans since the invention of debt. However! Shouldn't we credit Keen with the foresight to add debt to the model regardless of why he did it? Maybe he hadn't quite worked out the details of why that dD/dt term goes in there, but intuition guided him to include it. The inclusion lead to a model that Keen used to make qualitative predictions, therefore we should look at the qualitative properties of the models. I'll drop the prime on GDP' from here on out.
This is where that series of tests I discussed in
Part 1 comes into play. Most importantly: you cannot use a qualitative prediction to validate a model as a substitute for (qualitatively) validating it with the existing data. Let's say I have a qualitative model that qualitatively predicts that a big shock to GDP (and therefore employment by Okun's law) is coming because the ratio of debt to GDP is increasing. Add in a Phillips curve so that high unemployment means deflation or disinflation. Now how would that look generically (qualitatively)? It'd look something like this:
Should we accept this model because of its qualitative prediction? Look at the rest of it:
It was a NAIRU model with perfect central bank inflation/employment targeting that added in Keen's debt mechanism (trivially) when debt reached 100% of GDP. But here is Keen's model from "A dynamic monetary multi-sectoral model of production" (2011):
The qualitative prediction is the same, but the qualitative description of the existing data from before the prediction is very different. Here we have two "Theory versus data" graphs:
Actually the simplistic model is a much better description (measured by average error) of the data! But neither really captures the data in any reasonable definition of "captures the data".
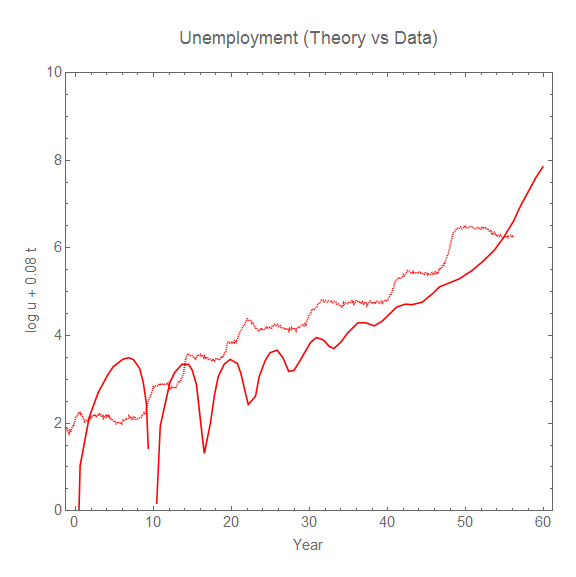
The issue with using Keen's models qualitatively is that they fail these qualitative checks against the existing data. Here are a couple more "Theory versus data" graphs (the first of real GDP growth is from the model above, the second is from Keen's
Forbes piece "Olivier Blanchard, Equilibrium, Complexity, And The Future Of Macroeconomics" (2016)):
And I even chose the best part of the real GDP data (the most recent 20 years) to match up with Keen's model. But there's a lot more to qualitative analysis than simply looking at the model output next to US data. To be specific, let's focus on the unemployment rate.
Unemployment: a detailed qualitative analysis
First, Keen's graph not only doesn't look much like US data as mentioned:
It doesn't look much like the data from other countries either (here the EU and Japan):
Additionally, Keen's graphs don't share other properties of the unemployment data. Keen's model has strong cyclical components (I mean pure sine waves here), while the real data doesn't. We can see this by comparing the power spectrum (Fourier transforms) [1] (data is dotted, Keen's model is solid):
We can see the unemployment data has a strong step-like appearance, which is due to the roughly constant rate of fractional decrease in the unemployment rate after a shock hits [2]. This property is shared with the data from the EU and Japan shown above. Keen's model has the unemployment rate decreasing at a rate that is proportional to the height of the shock. Instead of flat steps, this results in trenches after each shock that decrease in depth as the shock decreases.
We can also observe that the frequency of the oscillation in Keen's model is roughly constant (it slightly decreases over time). However the differences between the unemployment peaks in the empirical data are consistent with a random process (e.g. Poisson process).
There's a big point I'd like to make here as well: just because you see the data as cyclic it doesn't mean any model result that is cyclic qualitatively captures the behavior of the system. I see this a lot out there in econoblogosphere. It's a bit like saying any any increasing function is same as any other: exponential, quadratic, linear. There are properties of cycles (or even quasi-periodic random events) beyond just the fact that they repeat.
Anyway, these are several qualitative properties of the unemployment data. In most situations these kinds of qualitative properties derive from properties the underlying mechanism. This means that if you aren't reproducing the qualitative properties, you aren't building understanding of the underlying system.
In fact, exponentially distributed random amplitude Gaussian shocks coupled with a constant fractional decrease in the unemployment rate derived from, say,
a matching function yields all of these qualitative features of the data. Here's another "Theory versus data"
using this model [3]:
The underlying system behind this qualitative understanding of the unemployment data has recessions as fundamentally random, predictable only in the sense that the exponential distribution has an average time between shocks (about 8 years). These random shocks hit, and then at a constant fractional rate the newly unemployed are paired with job openings.
So how does Keen's model stack up against the heuristics I put forward
in my post on how to do qualitative analysis right? Well ...
- Keen's models generally have many, many parameters (I stopped counting after 20 in the model discussed above). The model discussed above The Lorenz limit cycle version from the Forbes piece appears to have 10. [4]
- If real RGDP is as above, then Keen's model does have a log-linear limit for RGDP growth. However, the price level fails to have a log-linear limit (since the rate goes from on average positive to increasingly negative, the price level will go up log-linearly and then fall precipitously).
- As shown, there is a time scale on the order of 60 years controlling the progression from cyclic unemployment to instability in addition to the roughly 7-8 year cyclic piece. This makes it pure speculation given the data (always be wary of time scales on the order of the length of available data, too).
- Keen's model is not qualitatively consistent with the shape of the fluctuations (per the discussion above).
- Keen's model is not qualitatively consistent with the full time series (per the discussion above).
The overall judgment is qualitative model fail.
...
Update 10 February 2017
One of the curious push-backs I've gotten in comments below is that Keen's model "is just theoretical musings", or that I am somehow against new ideas. The key point to understand is that I am against the idea of saying a model has anything to do with a qualitative understanding of the real world when the model doesn't even qualitatively look like the real world.
Keen himself thinks his model is more than just theoretical musings. He doesn't think the model just demonstrates a principle. He doesn't think these are just new ideas that people might want to consider. He thinks it is the first step towards the correct theory of macroeconomics. Here's the conclusion from Keen's "A dynamic monetary multi-sectoral model of
production" (2011):
Though this preliminary model has many shortcomings, the fact that it works at all [ed. it does not] shows that it is possible to model the dynamic process by which prices and outputs are set in a multisectoral economy [ed. we don't learn this because the model fails to comport with data]. ... The real world is complex and the real economy is monetary, and complex monetary models are needed to do it justice [ed. we don't know monetary models are the true macro theory]. ... Given the complexity of this model and the sensitivity of complex systems to initial conditions, it is rather remarkable that an obvious limit cycle developed [ed. limit cycles are not empirically observed] out of an arbitrary set of parameter values and initial conditions—with most (but by no means all) variables in the system keeping within realistic bounds [ed. they do not]. ... For economics to escape the trap of static equilibrium thinking [ed. we don't know if this the the right approach], we need an alternative foundation methodology that is neat, plausible, and—at least to a first approximation—right [ed. it is not]. I offer this model and the tools used to construct it as a first step towards such a neat, plausible and generally correct approach to macroeconomics [ed. it is not because it is not consistent with the data].
Keen's model does not "work", it does not capture the real world even qualitatively, it is not "right", and there is no reason to see this as a first step towards a broader understanding of macroeconomics because it is totally inconsistent with even a qualitative picture of the data.
In my view, Keen's nonlinear differential equations are travelling the exact same road as "rational expectations" approach of Lucas, Sargent, and Prescott. They both ignore the empirical data, but are pushed because they fit with some gut feeling about how economies "should" behave. In Keen's case, per JW Mason's quote above, where "credit squiggly GDP". With LSP [5], that people are perfect rational optimizers and markets are ideal. Real world data is seen through the lens of confirmation bias even when it looks nothing like the models. This approach is not science.
...
Footnotes:
[1] Interestingly, the power spectrum (Fourier transform) of the unemployment rate looks like pink noise with exponent very close to 1. Pink noise arises in a variety of natural systems.
[2] The constant rate is related to the linear transform piece and the fractional decrease is related to the logarithm piece.
[3] I also made this fun comparison of Keen's model, the data, and an IT dynamic equilibrium model:
[4] The random unemployment rate model produced from the information equilibrium framework has 2 for the mean and standard deviation of the random amplitude of the shocks, 2 for the mean and standard deviation of the random width of the shocks, 1 for the Poisson process of the timing of the shocks, and finally 1 for the rate of decline of the unemployment rate for a total of 6.