
I seem to have involved myself in a Twitter dispute with economist Roger Farmer about what it means to make macro models — or more broadly "the nature of the scientific enterprise", as Roger the economist kindly tried to explain to me, a physicist. Unfortunately, due to his prolific use of the quote tweet the argument is likely impossible to follow. You can see the various threads via this search.
Background
This started when I noted that Roger Farmer's claims about unemployment — in particular in papers supporting his claims that he cites here Farmer (2011) and here Farmer (2015) — are inconsistent with the long run qualitative behavior of the unemployment rate data. That is to say the models are not consistent with the empirical fact that the unemployment rate between recessions falls at a logarithmic rate of about −0.09/y in the US (BYDHTTMWFI: here's a recent NBER paper).
Let me say right off that I actually appreciate Roger Farmer's work — he does seem to think outside the box compared to the DSGE approach to macro that has taken over the field.
I am going to structure this summary in a series of claims that I am not making because it seems many people have confused requiring qualitative agreement with data with precise measurements of the electron magnetic moment.
Here we go!
I am not saying models with RMS error ε ≥ x must be rejected.
The funniest part about this is that in my figure that I use to show the Roger's model's lack of qualitative agreement actually shows the DIEM has worse RMS error over the range of the data Roger shows in his graph [2].
The thing is it's easy to get low RMS error on past data simply by adding parameters to a fit. This does not necessarily work with projected data, but in general more parameters often yield a better fit to past data and sometimes a better short run projection.
However, my original claim that started this off was that his model based on shocks to the stock market in the supporting papers was "disconnected from the long run empirical behavior of the unemployment rate". It's true that if you take the shocks to the unemployment rate and add the dynamic equilibrium of the S&P 500 model, you get a short run correlation that lasts from 1998 to about 2010:

I am not calling for Roger Farmer to stop working on his models.
It's fine by me if he wants to give talks, write blog posts about his model, or think about improving it in the privacy of his own research notebook. I would prefer that he grapple with the fact that the models are not qualitatively consistent with the data instead of getting defensive and saying that they don't have to pass that low bar. I believe models that are not qualitatively consistent with the data should not be used for policy, though — and that is one of Roger's aims.
It's true that a lot of ideas start out kind of wrong — it's unrealistic to expect a model to match the data exactly right out of the gate. And that's fine! I've had a ton of bad ideas myself! But there is no reason we should expect half-baked ideas lacking qualitative agreement with the data to be taken seriously in the larger marketplace of ideas.
So many comments on the feed were about working towards an insight or the models being just an initial idea that could be improved. Most of us don't get a chance to put even really good ideas in front of a lot of people, so why should we accept something that's apparently not ready for prime time just because it's from a tenured professor? I have a Phd and a lot of garbage models of economic systems that aren't even qualitatively accurate in my Mathematica notebook directory — should we consider all of those? In any case, "it may lead to future progress" is not a reason to say "oh, fine then" to models that aren't qualitatively consistent with empirical data.
What I am saying is that we should set the bar higher for what we consider useful models in macro than "it might qualitatively agree with data one day". We can leave discussion of those models out of journals and policy recommendations.
I am not saying we should apply the standards of physics to economics.
This goes along with people saying I shouldn't be applying "Popperian rejection" to economic models. First off, this misconstrues Popper who was talking about falsifiability as a condition for scientific theories as opposed to pseudoscience. Roger's models are falsifiable — I don't think they are pseudoscience. However, Popper didn't really say much about models being falsified despite the fact that lots of people think he did.
General Relativity is a better model than Newtonian gravity, but both models are falsifiable. We consider Newtonian gravity to be incorrect for strong gravitational fields, precise enough measurements in weak fields, or velocities close to the speed of light. We still use good old Newton all the time — I did just the other day for an orbital dynamics question at work. I fully understand the difference between a model that is an approximation and one that is supposed to be a precise representation of reality.
Popper, however, did not say anything about models that don't qualitatively agree with the data. That's because in most of science, such models are thrown out before they are ever published. Economics, especially macro, operates in a different mode where I guess they consider models that look nothing like the data. Ok, I know the time series data is an exponentially increasing amplitude sine wave and this model says it's a straight line, but hear me out!
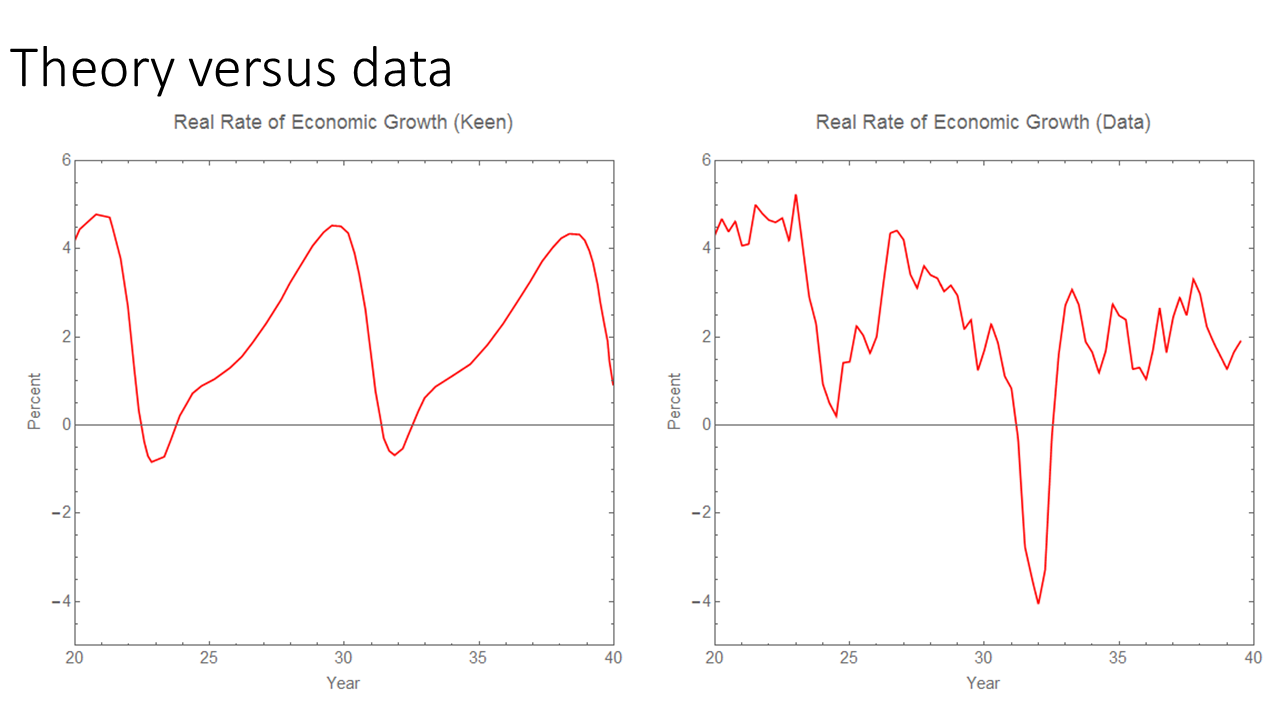
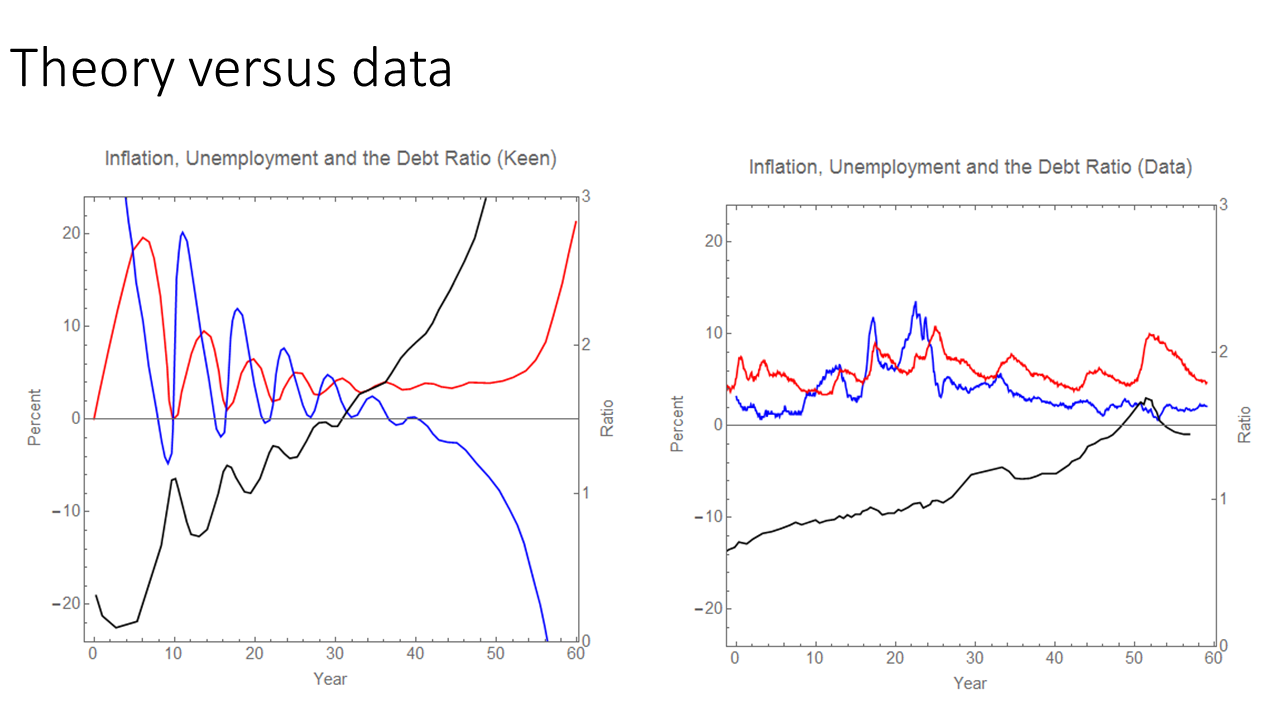
If the standards for agreement with the data are below qualitative agreement with the data, then there's really no reason to throw out Steve Keen's models [3]. But that's the problem — there are models that agree with the data! David Andofatto's simple model matches the data fairly well qualitatively! (It gets points 1 and 3 above and could be set to u* = 0 to get 2.) The existence of those models should set the bar for the level of empirical accuracy we should accept in macro models.
What I am saying is that there are existing models that more precisely match the data — and that is the standard I am using. It's not physics, but rather the performance other economic models. If you have a model that has worse RMS error, but has better qualitative agreement with the data, then that's ok to bring to the table. Overall, there seems to be far too much garbage that is allowed in macro because, well, there apparently wouldn't be any macro papers at all if some basic standards were enforced. When I say these models that aren't even qualitatively consistent with the data should be thrown out, I'm not talking about Popperian rejection, I am talking about desk rejection.
One last point ... what is the use of a model that doesn't qualitatively agree with data?
I didn't have a way to phrase this one as something I'm not saying. I literally cannot fathom how you can extract anything useful from a model that does not qualitatively agree with the data. This is lowest bar I can think of.
Yes this model looks nothing like the data but it's useful because I can use it to understand things based on ...
That ellipsis is where I cannot complete the sentence. Based on gut feelings? Based on divine revelation? If the model looks nothing like the data, what is anything derived from it derived from? The pure mathematical beauty of its construction?
It's like someone saying "Here's my model of a car!" and they show you a cat. Yes, this cat isn't qualitatively consistent with a car, but it's a useful first step in understanding a car. The cat gives me insights into how the car works. And you really shouldn't be using Popperian rejection of the cat model of a car because automobile engineering is not the same as physics. Making a detailed car model is unnecessary for figuring out how it works — a cat is perfectly acceptable. Eventually, this cat model will be improved and will get to a point where it matches car data well. The cat model also allows me to make repair recommendations for my car. You see the cat has a front and a back end, where the front has two things that match up with the car headlights, and yes the fuel goes in the front of the cat while it goes in the side of a car but that's at least qualitatively similar ...
...
Update 7 December 2020
Also realized Roger has made a major stats error here:
Jason Jason. @infotranecon I really don’t know where to start. 1. The unemployment rate is I(1) to a first approximation. 2. The S&P measured in real units is I(1) to a first approximation. The two series are cointegrated. The S&P Granger causes the unemployment rate.
Here's Dave Giles, econometrician emeritus extraordinaire:
If two time series, X and Y, are cointegrated, there must exist Granger causality either from X to Y, or from Y to X, both in both directions.
...
Footnotes
[1] The title is a reference to my old series that led, among other places, to realizing Wynne Godley has been maligned by people who ostensibly support him, and that Dirk Bezemer fabricated quotes in his widely cited paper.
[2] I do find it problematic that Roger not only cuts off the data early compared to data that was available at the time Farmer (2015) was published, but also cuts of data that was available at the time that would appear in the domain of his graph — data that emphasizes that the model does not qualitatively match the data. He also uses quarterly unemployment data which further reduces the disagreement.


No comments:
Post a Comment
Comments are welcome. Please see the Moderation and comment policy.
Also, try to avoid the use of dollar signs as they interfere with my setup of mathjax. I left it set up that way because I think this is funny for an economics blog. You can use € or £ instead.
Note: Only a member of this blog may post a comment.