I may have gotten into an argument with an anonymous commenter on the Economics Job Market Rumors forum whose entire argument seems to be on the order of "info theory is wrong LOL". Sometimes even this kind of arguing can be useful, though; it makes you look at the big picture.
See, the thing is, even if the information equilibrium model is not useful for economics, economists must have some view of the price mechanism as a communication channel. If there is information flowing in markets it has to originate somewhere, move through a channel and finally end up somewhere.
I tried to think of what that communication channel could be -- maybe this is wrong (LOL), but it's a start. So let's start with Shannon's A Mathematical Theory of Communication and his famous diagram:
 |
| Fig. 1: A communication channel. |
What we have is an information source on the left that is encoded and transmitted through a channel (where some noise can be added), to be received and decoded at the destination on the right side. A faithful reconstruction on the right side essentially requires getting the distribution of possible messages on the left side to equal the distribution of possible messages on the right side. For example, at a bare minimum, the distribution of letters in English words must be equal on both sides of the channel for communication (information transfer) to occur. In that case the transmitted information is equal to the received information, or I(Tx) = I(Rx).
In economics, the typical description of the price mechanism is as an information aggregator. All of the many details of e.g. weather patterns, the governments that have dominion over the available arable land, seed genetics and crop yields are compressed into a single number and its movements, e.g. the price of wheat. Agents buying and selling wheat are the source of information that is transmitted by the market and received by the market price.
 |
| Fig. 2: Modern economic view of the market as a communication channel. |
Even if we had a multidimensional normal distribution (made up of independent distributions) on one side and a normal distribution of price movements (all with the same variance V) on the other we'd still have
(k/2) log 2 π e V - (1/2) log 2 π e V = ((k-1)/2) log 2 π e V
of information loss. A more concrete example: imagine the set of outcomes you can get from rolling 5 dice and trying to encode those outcomes with the set of outcomes you can get from rolling a single die -- you basically lose 4 dice of information.
In this picture, I(Tx) >> I(Rx), which is effectively the view of Stiglitz (2000) [1]
"The exchange process is intertwined with the process of selection over hidden characteristics and the process of providing incentives for hidden behaviors."
The realized real-world distribution over those characteristics and behaviors is the "complex multidimensional distribution" in the diagram above. The lost four dice of information in the example are these "hidden characteristics". Basically, you lose something going from the distribution on the left side to the single-dimensional distribution of price movements on the right side.
Economics had been working with a rather good solution to this problem for the previous 200 or so years: utility. Instead of a complex multidimensional distribution on the left side, economic agents have a single-dimensional distribution of utility for e.g. wheat. When the price of wheat is high relative to a given agent's utility, the agent doesn't buy it. We replace the previous diagram with this one:
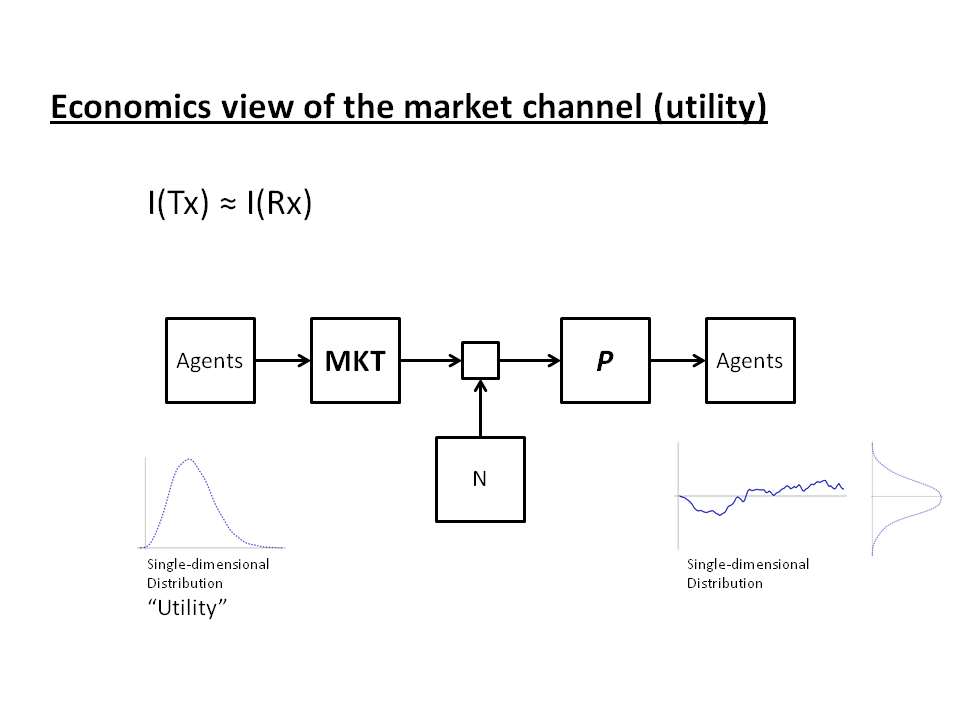 |
| Fig. 3: Utility view of the market as a communication channel |
and the information on the right side is approximately equal to the left side: I(Tx) ≈ I(Rx).
[Note that this diagram is an information transfer model and effectively says that utility of a good is in information equilibrium with the price of that good.]
Of course, markets aren't perfect and this description doesn't empirically match up with what happens in the real world (the impetus for the work of Stiglitz to show that the real picture is more like Figure 2). Let's look at the information equilibrium diagram:
 |
| Fig. 4: Information equilibrium view of the market as a communication channel. |
How does the information equilibrium view differ from Figures 2 and 3? First, we have complex multidimensional distributions on both sides. Supplies and demand for wheat is different in different locations around the world. Different countries use different amounts of wheat (in some places e.g. rice is the dominant carbohydrate source), and different uses of wheat are more valuable than others (ethanol, bread). Wheat is subsidized in some countries (and states within those countries). Some people aren't able to afford as much as others. In a functioning price system, the spatial and temporal distribution of demands for wheat is equal to the distribution of supplies of wheat. There is a loaf of bread for you to buy at the price you want at the store in your neighborhood.
Second, we've moved the price from being the receiver (aggregator) of information to simply being a detector of information flow. Prices are high when small changes in the distribution on the right cause (or are caused by) large changes in the distribution on the left. Prices are low when large changes in the distribution on the right cause (or are caused by) small changes in the distribution on the left. When the distributions change the same amount, we say the price is in equilibrium [2]. The price is still not a perfect detector of information, but over time as the distributions on the left and right evolve, the price will reach an equilibrium.
In this picture I(Tx) ≈ I(Rx) for an ideal market. However, all we can really guarantee is that I(Tx) ≥ I(Rx), so there may well be times when the market isn't ideal and I(Tx) > I(Rx).
Just because it is different, doesn't mean it is right. And if it is right, that doesn't mean it is useful. Maybe in the real world I(Tx) >> I(Rx) most of the time. However, economists must have some picture in their head of the price system as a communication channel if it moves information around, and you can't violate mathematical theorems.
Otherwise ... econ is wrong LOL.
Update 3/23/2015
In looking again at the utility solution, there is still a massive loss in information going from preferences to utility. Well-behaved preferences (essentially ensuring transitivity so that preferences represent a well-ordered set and therefore roughly equivalent to a real-number representation like utility) wouldn't have as much of an issue, but are empirically false.
The mathematical space of preferences cannot be mapped one-to-one to the manifold of utility -- many different sets of preferences will map to the same utility.
What we have is a water balloon of information. If we try to squeeze it down into utility, it bulges out on another side.

Footnotes:
[1] "THE CONTRIBUTIONS OF THE ECONOMICS OF INFORMATION TO TWENTIETH CENTURY ECONOMICS" JOSEPH E. STIGLITZ (2000). (H/T to afinetheorem for linking to it recently.)
[2] One can measure the information difference between two distributions with the Kullback-Liebler divergence. When one distribution changes, that represents a change in information. That information flows through the market an is registered as the commensurate change in the other distribution.
quick question, what kinds of assumptions of randomness do I need to reach information equilibrium ? the P. Fielitz, G. Borchardt paper is a little too information theoryisch for me...so i have trouble coming up with examples outside of signal process that should satisfy their properties..
ReplyDeleteHi LAL,
DeleteIf you are referring to whether a random process must be Markov or something similar, there are not any restrictions of that nature. On this blog I've actually assumed that the processes could be completely deterministic, just sufficiently complex to appear random.
I've used AR processes e.g. here:
http://informationtransfereconomics.blogspot.com/2014/03/the-monetary-base-as-sand-pile.html
Most stochastic processes should work. I might be misunderstanding your question, though.
that definitely answers part of it...the rest is more along the lines of once I have made the assumptions I want about the system (or lack of assumptions as seems to be the real power of this method) when should I be in information equilibrium? in the context of the economy you have mentioned correlation of actions/expectations of economic agents...what is the general principle that such behavior are in violation of
DeleteAh, I see. In that case the answer is maximum entropy:
Deletehttp://en.wikipedia.org/wiki/Principle_of_maximum_entropy
In thermodynamics, you are in equilibrium when entropy is maximized (or free energy or Gibbs free energy).
http://en.wikipedia.org/wiki/Thermodynamic_equilibrium#Conditions_for_thermodynamic_equilibrium
Quick suggestion:
ReplyDeleteMaybe it's not such a good idea to try to get a holistic paper published but to publish a series of papers where you prove something small-ish using this theory. If you talk within the context of economic orthodoxy while incorporating ideas from this context, people may be a lot more receptive.
Thanks for the advice. Actually, the first paper was going to be mostly just reproducing a bunch of well-known (and old) macro models and stylized facts (e.g. how you would construct the IS-LM model, the quantity theory and Okun's law)
Deletehttp://informationtransfereconomics.blogspot.com/2015/02/information-equilibrium-paper-draft.html
The only new bit will be a "small-ish" result that assumptions like Calvo pricing may actually be trying to capture an "entropic force" (in this case, nominal rigidity) as a micro effect -- and maybe such assumptions are not necessary.
The post at econjobrumor asks you whether you've read Duncan Foley's works about statistical equilibrium. Also, the formula for I_d and I_s in your information transfer model has n_s and n_d, which suggests that if there is more demand and more supply, there is more information. However, this does not seem to be necessarily right. If I am getting your model wrong, please inform me.
ReplyDeleteHello,
DeleteThanks for the heads up.
I commented on the thread, but to answer here: I have read several of Foley's papers -- when I thought I stumbled on a novel approach, I immediately tried to search as much of the literature I could to make sure I wasn't reinventing the wheel or saying something obviously wrong. Foley's work came up, but he focuses on utility maximization (which may be the information equilibrium model I mention in the post above in brackets).
Regarding your other question, here's what I wrote on the econ rumors thread:
The additional information comes from the increased number of bits required to describe the allocation of an increased number of goods sold/demanded. If there are 3 widgets and two agents, there are 4 ways to allocate the widgets (3 + 0, 2 + 1, 1 + 2 and 0 + 3). If there are 4 widgets and 2 agents, there are 5 ways. That's an increase in the information content of an allocation of about 1/3 of a bit: log_2(5) - log_2(4) = 0.32.